![]() What if a search engine knew who your friends were and delivered results based on their actions and content across the Web? Today at the DEMO conference, an Israeli startup called Delver (formerly Semingo) is coming out of stealth and announcing its upcoming launch as a semantic social graph search engine.
What if a search engine knew who your friends were and delivered results based on their actions and content across the Web? Today at the DEMO conference, an Israeli startup called Delver (formerly Semingo) is coming out of stealth and announcing its upcoming launch as a semantic social graph search engine.
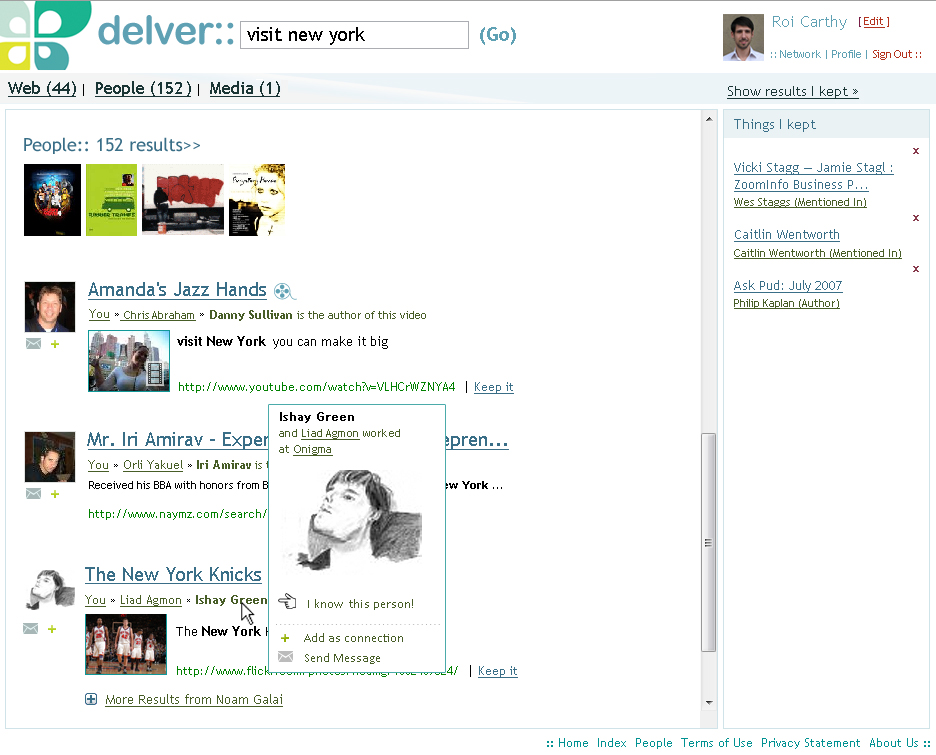
Delver is attempting to solve two key search-related problems. The first is that current search engines do not take into account the identity of the searcher. For example, a teenager and a senior citizen performing the same query will get exactly the same results. The second is that current search engines do not allow users to search for information created and referenced by their own social graph. This is an important point because, let’s face it, social networking doesn’t offer much functional value beyond allowing people to connect with one another. The fact that you have 300 friends on Facebook, 200 on MySpace and 100 connections on LinkedIn doesn’t actually help you locate information. This is where Delver comes in. Search for “New York,” and the results that will pop up will be blog posts from people you know that mention or are about New York, or Flickr photos, YouTube videos, Delicious bookmarks, and the like.
 The technology, which has been in development since 2005, combines search technologies, semantics and Natural Language Processing (NLP). Delver begins by crawling the Web in order to map users’ social connections. The information it finds on social networking profiles, blogs, bookmarks, photo and video-sharing sites is then cross-linked to the searcher’s social graph, which is built on-the-fly. Delver then prioritizes its results based upon the searcher’s social graph, thereby improving the relevancy of the results. Since every person’s social graph is unique—much like a fingerprint—the same Delver query will produce significantly different results for each person—as reflected through the collective experiences of each person’s contacts.
The technology, which has been in development since 2005, combines search technologies, semantics and Natural Language Processing (NLP). Delver begins by crawling the Web in order to map users’ social connections. The information it finds on social networking profiles, blogs, bookmarks, photo and video-sharing sites is then cross-linked to the searcher’s social graph, which is built on-the-fly. Delver then prioritizes its results based upon the searcher’s social graph, thereby improving the relevancy of the results. Since every person’s social graph is unique—much like a fingerprint—the same Delver query will produce significantly different results for each person—as reflected through the collective experiences of each person’s contacts.
Using Delver doesn’t require users to sign-in, they can just enter their names (and some additional identifying details such as city, in the case of a common name). An email address will also allow Delver to leverage the popular social networks to locate users’ social graphs.
Registered users can claim their profile and authenticate the sources they want to associate with. This means that if I provide the username and password of my Flickr account, Delver considers this account to be mine and will not allow any other user to claim it. Placing authentication aside for the moment, users can indeed claim to be other people. The information Delver crawls is public so there’s no privacy issue here. There is also no real benefit to users who would do such a thing, in fact, it would be rather pointless. For example, I can Delver Michael Arrington’s social graph, but that would generate results that are relevant to him and not to me. However, as mentioned above, Arrington can easily claim his profile and that would be the end of that.
Founded in June 2007, Delver is currently based in Herzelia, Israel and is due to open a US office in the spring. The 20-strong team is headed by Liad Agmon who was co-founder and CTO of Onigma, a security company in the Data Loss Prevention space, and sold to McAfee less than two years after inception for $20M.
Delver will launch its private beta in March and we will make sure TechCrunch readers will be among the first to take it out for a spin.