Extracting meaning from the Web is huge project that is very difficult to do at large scale. Keyword search only skims the surface of meaning locked in Web pages. Various semantic search technologies try to go deeper by adding structured data to web pages so that the Web can be treated more like a database. But adding semantic metadata to the Web is laborious and time-consuming. Just look at Twine. It’s approach so far has been to add semantic data only to the Web pages members save to the service.
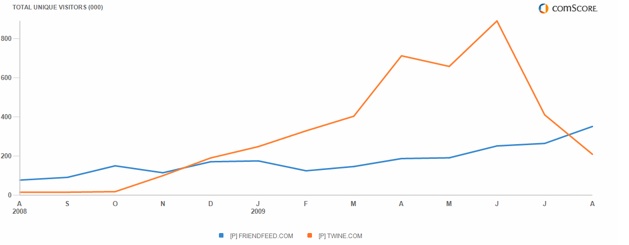
While it appeared like Twine was finally getting some traction earlier this year, it’s fallen by the wayside. Traffic is way down (see chart below), partly because it is no longer buying traffic with ads and partly because of changes to the way Google indexes the site. Bottom line is that is that beyond a hardcore following of about 250,000, Twine does not have broad appeal.
But CEO Nova Spivack and his team at Twine have been busy working on something else entirely, to the point that the current Twine service is pretty much on autopilot. In the video above, Spivack gives a sneak peak at what his team has been working on. Codenamed T2, it is complete departure from the navel-gazing approach of Twine 1.0. It is a big step towards creating a semantic search engine that might eventually scale across the Web—exactly the kind of swing for the fences type of idea we like to see at TechCrunch.
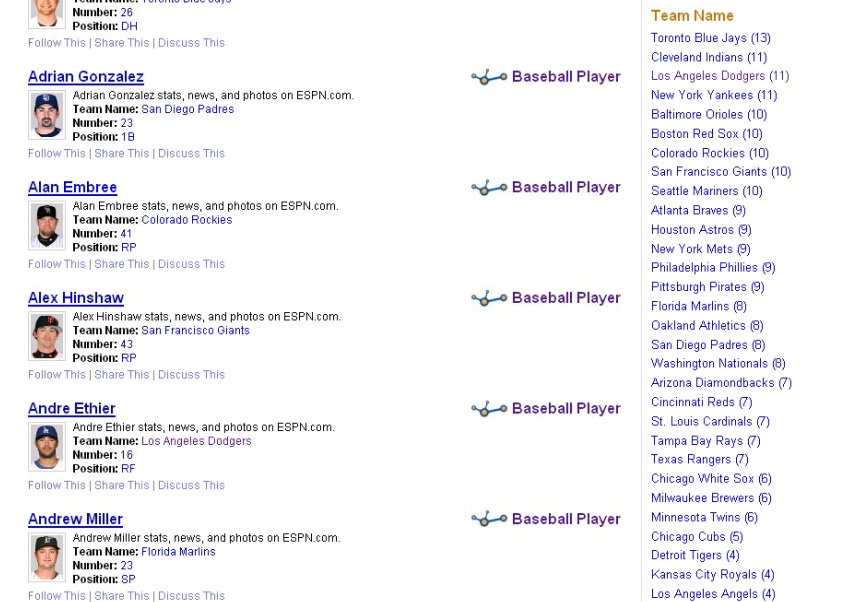
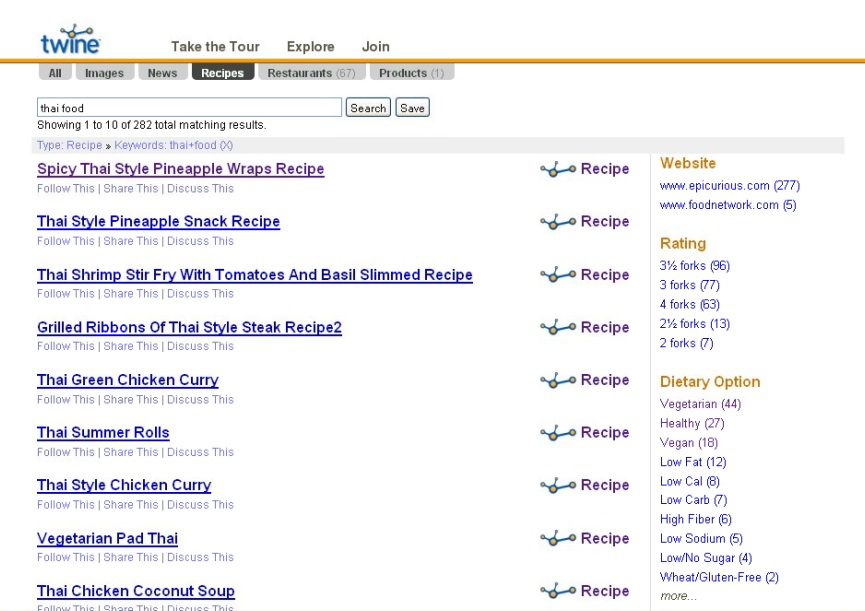
When T2 launches, hopefully by the end of the year, it will be a demonstration of what semantic search could be. T2 will have a semantic index of the top 50 to 100 sites across major categories such as food, health, sports, music, finance, television, politics, tech and movies. In those categories, T2 should provide really good guided search. If you search for “baseball” you will get a list of baseball players, along with categories on the side to refine the list such as by position or team name. When you type in “thai food,” you can select the Recipes tab and then filter by food site, rating, main ingredient, and so on. Or you can select the restaurant tab and drill down by city, hours of operation, etc.
You’ll find this type of guided search on Bing, with the categories changing based on the initial search term. But Twine does things differently.
What Twine has done, basically, is speed up the rate at which it can look at a raw Web page and create semantic metadata for it. Bing sometimes does this via natural language processing, through the technology it bought with Powerset. That takes a lot of computation. It also employs other methods. Twine’s approach is more to create a set of semantic tags for each page.
There are already standards for doing this, such as RDF and OWL, but most Webmasters don’t bother adding such tags to their sites. If they happen to be there, Twine can read them, but it can also make a good guess as to what is on the page and assign its own tags to the page. In order to try to make it easier for Web developers to tag their sites, Twine is also working on developer tools such as an Ontologies Editor. This lets anyone with domain expertise define the different concepts and tags which would characterize a page about a particular topic, such as a recipe or a baseball player or a car. For example, a recipe might be contain concepts such as ingredients, difficulty level, an author, and a a date. There are literally millions of potential properties that can be matched to different concepts. The collection of all of these together for a specific topic is an ontology.
There can literally be hundreds of thousands of ontologies for every conceivable topic. If Twine knows what ontology to apply to a given Web page, it can do a better job applying semantic tags to it and extracting data. Twine wants to create an open directory of these things, which will be like a SourceForge for ontologies where anyone can contribute and make them better. You can watch this video for more details.
All of this might seem a bit abstract, but if we could ever get to the point where the most important pages on the Web have semantic tags, it will be a lot easier for computers to know what they are about. And to the extent that data is locked in those pages, the Semantic Web will turn that data into something that can be computed. As these tags get applied to more and more information, they could eventually help filter stream data as well that everyone is increasingly drowning in.
Whether or not Twine will be the company to deliver any or all of this is a long shot, but it is definitely something worth swinging for.