 It’s been a long time coming, but the computer industry is finally making headway in the switch from old-fashioned, platter based hard drives to the solid state drives (SSDs) found in iPhones and many other electronics. The benefits are obvious: unlike their platter-based counterparts, SSDs have no moving parts, and they’re also significantly faster for many tasks. Unfortunately most software, both server-side and otherwise, has been optimized for the older drives and the physical limitations that come with them. RethinkDB is a new startup that’s looking to capitalize on this problem by building a storage engine for mySQL databases that’s fully optimized for SSD drives, bringing with it large speed boosts and a number of features sure to catch the eye of many developers.
It’s been a long time coming, but the computer industry is finally making headway in the switch from old-fashioned, platter based hard drives to the solid state drives (SSDs) found in iPhones and many other electronics. The benefits are obvious: unlike their platter-based counterparts, SSDs have no moving parts, and they’re also significantly faster for many tasks. Unfortunately most software, both server-side and otherwise, has been optimized for the older drives and the physical limitations that come with them. RethinkDB is a new startup that’s looking to capitalize on this problem by building a storage engine for mySQL databases that’s fully optimized for SSD drives, bringing with it large speed boosts and a number of features sure to catch the eye of many developers.
The company, which is part of the latest batch of Y Combinator-funded startups, is in fairly early stages (it started developing the product only two months ago), but it’s already making some substantial headway in the features it can offer. Among these are live schema changes, which allow developers to make significant modifications to their database structure without having to go through complex sync and backup procedures. It also offers lock-free concurrency, which means users will be able to read from the database even while other users are writing to it. And it’s an append-only database, which means developers can quickly recover in the event of a system failure.
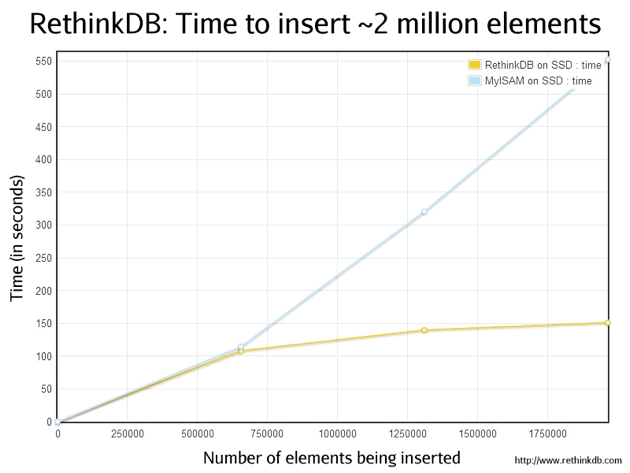
RethinkDB is also taking a relatively novel approach to its development, at least as far as database storage is concerned. It’s following the “release early, release often” mantra, which it’s kicking off with the release of an early developer pre-alpha, which you can download and try out for free (the company says that implementing the software is quite easy because of the way MySQL handles storage engines). However, given that you’re going to be using this to manage your data, it is absolutely vital that you use this for testing purposes only — make sure you have any crucial data stored elsewhere. The company hopes to use developer input over the next few months to improve the product up until its release.
RethinkDB plans to have its commercial product out the door in the next six months, with an enterprise-level pricing structure that charges on a per-CPU basis (with support included).