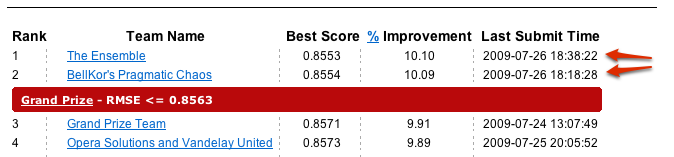
Who knew statistical computing competitions could be so cut throat? Since we reported on the contest last night, two teams in the Netflix Prize have spent the last few hours jumping back and forth on the Netflix leaderboard as the three-year-long competition ticked into its final moments, with last minute sniping submissions coming from both sides. Finally, the results are in: The Ensemble has managed to come from behind to upset BellKor’s Pragmatic Chaos with a top submission of 10.10% — an improvement of .01% — only 4 minutes before the contest closed.
Who knew statistical computing competitions could be so cut throat? Since we reported on the contest last night, two teams in the Netflix Prize have spent the last few hours jumping back and forth on the Netflix leaderboard as the three-year-long competition ticked into its final moments, with last minute sniping submissions coming from both sides. Finally, the results are in: The Ensemble has managed to come from behind to upset BellKor’s Pragmatic Chaos with a top submission of 10.10% — an improvement of .01% — only 4 minutes before the contest closed.
It’s been a long road to get here. Over the last three years computer science teams around the world have been vying for the Netflix Prize — a competition that invited teams to try to improve on Netflix’s movie recommendation algorithm by 10%, with a reward of $1 million to the best submission. Since then teams have gotten progressively closer to the magical 10% mark, but it wasn’t until last month when a number of top teams joined forces to form BellKor’s Pragmatic Chaos that the barrier was finally broken, with a score of 10.08%. However, their announcement kicked off a 30 day last call period where other teams were invited to make their final submissions.
Last night, a team called The Ensemble managed to one-up team BelKor with a score of 10.09%, less than 24 hours before the close of the competition. Things were looking bad for team BellKor (some suggested that they might be out trying to drown their sorrows). But the team was clearly still hard at work — it managed to tie the Ensemble with a score of 10.09% with only around 24 minutes remaining in the competition. But they were to be foiled once more: with only four minutes left, The Ensemble struck back with a score of 10.10% to regain the top spot on the Netflix leaderboard. Soon thereafter a notice went up on the Netflix homepage stating that there were to be no more submissions.
This is all very exciting, but there’s a reason that Netflix has not yet annouced the winner, even though the leaderboard is quite clear. That’s because the Netflix prize is actually based on two sets of data. The first is called the Quiz set, which is used to publicly display how a team is faring to the public and to determine when the contest would kick into its 30 day last call mode. But the set that really matters, the Test set, is still a secret, and nobody knows if The Ensemble or team BellKor performs better. Netflix will make the final contest announcement in the next few weeks.
Update: Yehuda Koren of BellKor’s Pragmatic Chaos has posted on the contest’s forums that BellKor came out with the lowest Test score, though it appears that Netflix has yet to confirm this.
Thanks to Almir Karic for the tip.