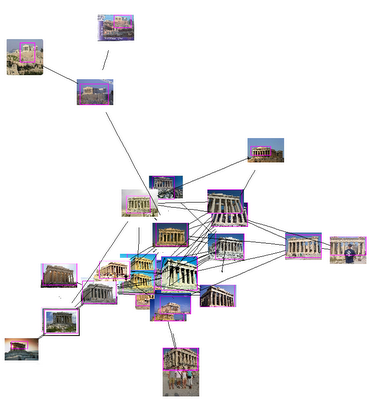
Image recognition is still one of those things that humans find easy to do but computers keep stumbling over. Some Google researchers published a paper describing progress they are making in teaching computers how to identify famous landmarks, which may eventually be applied more broadly to image search in general.
In a blog post, Jay Yagnik, the head of Computer Vision Research at Google, writes:
While we’ve gone a long way towards unlocking the information stored in text on the web, there’s still much work to be done unlocking the information stored in pixels.
In the experiment, the researchers fed “an unnamed, untagged picture of a landmark” found on the Internet and the system would spit back the name and location of the landmark, such as the Acropolis in Greece. Each untagged photo was be compared to 40 million GPS-tagged images on Picasa and Panoramio (both owned by Google), as well as related photos found through Google Image Search. Using clustering and new image indexing techniques, the Google researchers were able to identify untagged photos of the same landmarks from different angles and under various lighting conditions.
The researchers report that their system can identify 50,000 landmarks with 80 percent accuracy. I’m not sure that’s quite good enough to even roll that out in a beta product, but if Google can get it to 90 percent or 95 percent that would start to be consumer-friendly. Over the past few years, there’s been a lot of progress in image recognition, especially with facial recognition For instance, Face.com does a particularly good job with Facebook photos. But buildings and objects may be pose a different set of image-recognition challenges.