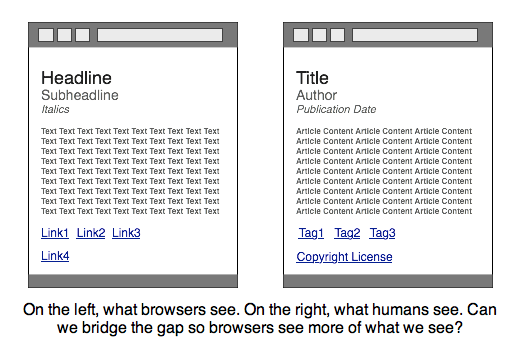
Earlier today Google announced that it was going to begin limited support of RDFa, a framework that allows web developers to incorporate structured metadata into their sites. To most people, this probably doesn’t sound particularly exciting, but it’s an important step that may indicate that the search giant is going to embrace structured data on the web – something that it has long shied away from.
I’m not going to get into the specifics of the RDFa standard (if you’d like a more thorough explaination you can find one here and here). But the benefits of using such semantic tagging can be seen in a few basic examples. If I was to write a post that mentioned “The President” without naming him, Google probably wouldn’t realize that I was talking about President Obama – it might think I was referring to another US president, or perhaps the leader of a company. But using RDFa I could tag the words “The President” with “Barack Obama”. That tag would be visible to machines spidering the page for indexing (resulting in smarter search results), but wouldn’t be shown to users reading the post. In effect, it’s a way to tell search engines about your content without exposing your visitors to extraneous text.
RDFa tags will also allow search engines to identify structural data on a web page and present it in search results (Google is using it to generate its rich snippets). And browsers could potentially read the data and use it to present maps or other elements outside of the web page.

Mark Birbeck, who first proposed the standard and will be speaking at a conference on the semantic web this June, says that this is a big step for Google. He explains that Google has always tried to use its algorithms to derive context from the content on webpages. This usually works pretty well, but as we’ve noted before, there are some things that algorithms just can’t identify properly (at least, not yet).
Now, it may be some time before we start seeing any real benefits from Google’s implementation of RDFa. For starters the search engine is only using it in a limited fashion, and it isn’t clear how long it will take for Google to begin incorporating it in other ways. But the standard is already spreading without Google’s help – Yahoo supports RDFa, and many sites including the UK government are implementing it too. Of course, with its dominant market share Google’s stamp of approval is huge for RDFa’s acceptance, and we’ll probably begin to see more services follow suit (Drupal 7, for one, will include it by default).
That said, not everyone is happy with the way Google is using the standard. There are complaints that Google is using a hobbled implementation of RDFa, ignoring some of the established conventions that many webpages have already used to tag their data. Birbeck acknowledges that Google could have implemented RDFa better, but says that “the only reason they can even raise the question of whether Google used the right vocabulary is because they are using RDFa now.. And that is huge.”