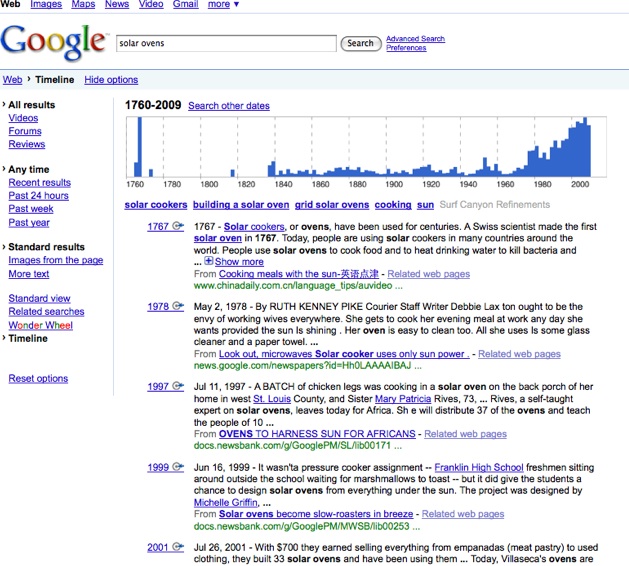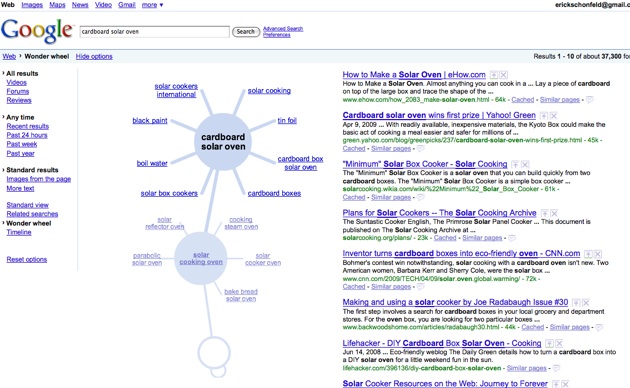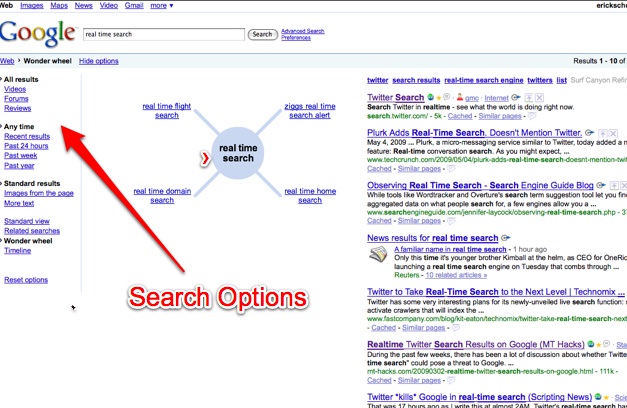
Google has just launched a new “search options” feature on its main search page. When you click on “Search options” you can filter your search by different types of results (videos, forums, and reviews), by time (recent, past 24 hours, past week, past year), as well as seeing related searches, a “wonder wheel” view, or a timeline view.
At Google’s Searchology event, which is going on right now, Marissa Mayer listed the following as the hardest unsolved problems in search:
– Finding the most recent information
– Expressing that you want just one type of result
– Assessing which results are best
– Knowing what you’re looking for
– Expressing your searches in keywords
Notice that real-time search is the No. 1 problem. (Twitter and a bunch of startups from OneRiot to Tweetmeme are also working on it, with the latter two launching their own real-time search efforts today). And it certainly is a problem for Google, even with the new recent results option. Try searching for any of teh top trending results on Twitter right now like Miss California (vs. Twitter search results) or Star Trek (vs. Twitter results), and you don’t even get any Twitter results on Google.
While real-time search is still a big problem, it is not the only problem. Some of the new options address the difficulty of searching back through time. The recent results get as real-time as Google can get, but you can also expand the timeframe. And you can look at an actual timeline of results, which looks for dates within results and then places them chronologically (this is sort of hit or miss—just because a date is mentioned in a text does not mean the entire result is about or from that period of time). Google now also lets you see related searches as an option. And the Wonder Wheel is more of a visual aid to see how different related topics are clustered together. When you click on any spoke of the wheel, it then causes that search term to be at the center. We’ve seen many of these techniques in the past, but Google is giving them a higher profile by putting them in its main search page..