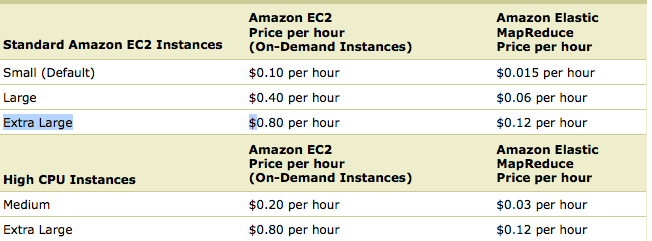
![]()
Slowly but surely, Amazon keeps adding capabilities to its cloud computing services. What started out as pay-by-the-drink storage (S3) and computational processing (EC2), now includes a simple database (SimpleDB), a content delivery network (CloudFront), and computer-to-computer messaging (SQS). And today Amazon added a web-scale file system data processing engine with Amazon Elastic MapReduce. (It is a framework for accessing data stored in file systems and databases).
This is actually a big deal because it allows developers to better take advantage of the massive computing power Amazon has to offer and create applications which process huge reservoirs of data (conveniently stored in Amazon S3) in parallel. MapReduce is the name of the data processing framework Google created to index and search the Web. It literally breaks up huge computational tasks and spreads them to different servers. This is called mapping the data. Once each processor is done with its portion of the math problem, it sends the result back so that all the different partial answers can be combined and then “reduced” into one final answer.
Amazon is using Hadoop, which is the open-source version of MapReduce. Yahoo also started using Hadoop last year. While Google and Yahoo use this technique for searching the Web, it can be used for any data-intensive computational problem. Amazon lists the following examples: “web indexing, data mining, log file analysis, machine learning, financial analysis, scientific simulation, and bioinformatics research.” Indeed, Hadoop is also the underlying technology used by IBM in its Blue Cloud initiative.
There is even a startup called Cloudera, which offers its own Hadoop computational services on top of Amazon’s EC2. They just got a huge competitor. But more startups can now create Web-scale applications at a fraction of the cost they could before.