![]()
The Financial Times Group, which is owned by the British publisher Pearson, is not exactly the place you’d expect to find the latest search engine. But a startup deep within the bowels of the organization called FT Search is launching one at 8PM ET tonight called Newssift. It is a semantic search engine that sifts through business news, and it is not half bad, especially for bigger companies and broader topics.
Robin Johnson, the CEO of FT Search, used to run the Financial Times in the U.S. as its president. He’s been working on Newssift for the past two years, and currently employs a team of 25 people. “The object was to create a tool to allow a busy business person to assess what is the skinny on a problem they do not know the answer to,” he tells me.
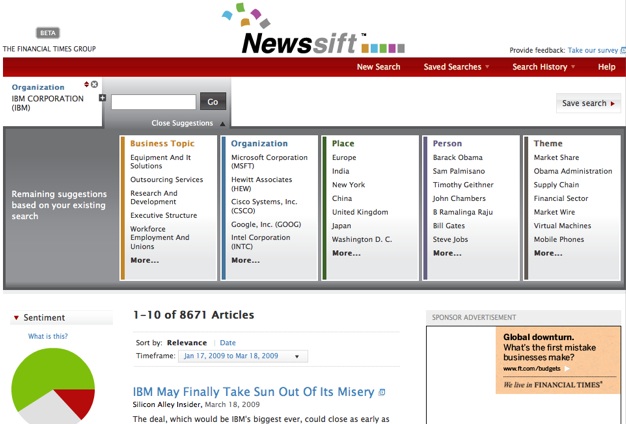
Newssift indexes about 4,000 business news sources, from online newspapers and blogs to news portals and research sites. It is ingesting about 120,000 articles a day right now and applying semantic tags to each one. In the end it can categorize each article by business topic, organization, place, person, and theme. When you type in a search term, each of those columns gets filled in with associated keywords, allowing you to drill down to exactly what you want even if you are not sure at the outset what you are looking for. The back-end clustering search is powered by Endeca. The tagging and data extraction is done by technology from NStein, the sentiment analysis is provided by Lexalytics, and ReelTwo does the categorization.
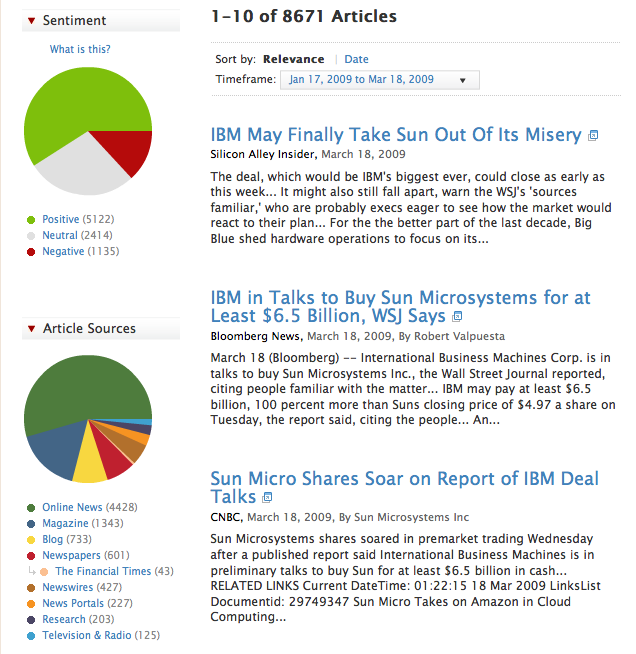
A search for “Sun Microsystems” brings up further suggestions for refinement, including “IBM,” “Jonathan Schwartz,” and “market share.” You sort of graze around, adding new keywords as they are presented to you. Each keyword you select is added to your string, and corresponding article results appear below. A sentiment pie chart indicates what percentage of the stories are positive, negative, or neutral. Another one breaks the results down by source (Online News, Magazines, Newspapers, Blogs, Research). Clicking on any shaded area filters the results further.
Searches can be saved, creating an interesting prospective news search tool. You can create your own memetracker for any industry or topic. I am not sure I would use Newssift every day to stay on top of the latest news, but I can see it as a useful research tool when I have to really dig deep into a topic. It does better with business news than technology. Still, it is worth checking out in that it employs several subtle navigational techniques that make it more of a discovery engine than a search engine.