What if you could peer into the thoughts of millions of people as they were thinking those thoughts or shortly thereafter? And what if all of these thoughts were immediately available in a database that could be mined easily to tell you what people both individually and in aggregate are thinking right now about any imaginable subject or event? Well, then you’d have a different kind of search engine altogether. A real-time search engine. A what’s-happening-right-now search engine.
In fact, the crude beginnings of this “now” search engine already exists. It is called Twitter, and it is a big reason why new investors poured another $35 million into the two-year-old startup on Friday. Twitter is not the only company trying to solve this problem. Facebook, FriendFeed, and even Google are trying to crack it, but Twitter has a decided advantage in that it is capturing the vast majority of the real-time thought stream on the Web (because more people enter their thoughts directly into Twitter’s database than any other, and are doing so at an increasing rate).
What makes Google and other search engines so valuable is that they capture people’s intent—what they are looking for, what they desire, what they want to learn about. But they don’t do a great job at capturing what people are doing or what they are thinking about. For thoughts and events that are happening right now, searching Twitter increasingly brings up better results than searching Google.
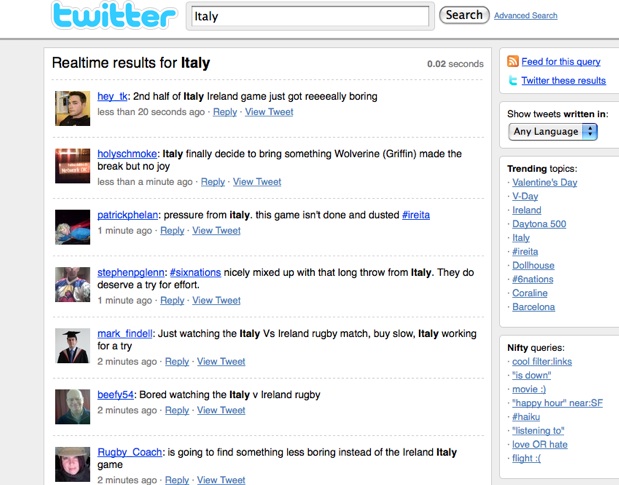
Whether you want to know how people are mentally gearing up for this week’s Mobile World Congress in Barcelona or what they are thinking about today’s Ireland vs. Italy rugby match, searching Twitter will give you a pretty good smattering of sentiment and opinion. It is also a lot faster at getting out the essential details about breaking news, such as the Mumbai attacks or the plane that landed on the Hudson.
Twitter’s search engine is powered by Summize, a startup it acquired last July. But it also developed a feature called Track, currently disabled but coming back soon, that allowed people to follow the mention of specified keywords. John Borthwick, an investor in Summize (and thus now an investor in Twitter), explained in a blog post earlier this month ago why he thinks that “Twitter search changes everything.” Excerpt:
Imagine you are in line waiting for coffee and you hear people chattering about a plane landing on the Hudson. You go back to your desk and search Google for plane on the Hudson — today — weeks after the event, Google is replete with results — but the DAY of the incident there was nothing on the topic to be found on Google. Yet at http://search.twitter.com the conversations are right there in front of you. The same holds for any topical issues — lipstick on pig? — for real time questions, real time branding analysis, tracking a new product launch — on pretty much any subject if you want to know whats happening now, search.twitter.com will come up with a superior result set.
. . . How is real time search different? History isn’t that relevant — relevancy is driven mostly by time. . . . This reformulation of search as navigation is, I think, a step into a very new and different future. Google.com has suddenly become the source for pages — not conversations, not the real time web. What comes next? I think context is the next hurdle. Social context and page based context. . . . Twitter search today is crude — but so was Google.com once upon a not so long time ago.
Twitter may just be a collection of inane thoughts, but in aggregate that is a valuable thing. In aggregate, what you get is a direct view into consumer sentiment, political sentiment, any kind of sentiment. For companies trying to figure out what people are thinking about their brands, searching Twitter is a good place to start. To get a sense of what I’m talking about, try searching for “iPhone,” “Zune,” or “Volvo wagon”.
Why can’t Google simply index Twitter? It does, but its search results give more weight to links than to time. It could create a new search product along the lines of Blog Search or News search that is geared more towards Micro-messaging services such as Twitter, FriendFeed, and the rest. But what it really needs to go beyond simply indexing Twitter after the fact. IVP partner, and Twitter investor, Todd Chaffee, suggests:
If they were really smart they could partner with Twitter and make Twitter their real-time feed.
Doing that would require Google to “affirm Twitter’s dominance in this category and the importance of the Twitter data stream,” contends Borthwick. But so far, Google has pretty much flubbed this opportunity to open up real-time search. It bought Twitter competitor Jaiku, only to shut it down. And now it is hoping to create a counterweight to Twitter’s growing strength in real-time data by open-sourcing Jaiku. Good luck with that one.
Listening to Twitter’s investors gives a good sense of how they think Twitter can become a game-changer in real-time search. While it is instructive, it is also important to note that much of this vision has yet to materialize. Twitter’s current search is extremely crude, as Borthwick readily admits. It simply brings up the most recent Tweets with the keyword you are looking for. There is no ranking or clustering beyond that.
An undifferentiated thought stream of the masses at some point becomes unwieldy. In order to truly mine that data, Twitter needs to figure out how to extract the common sentiments from the noise (something which Summize was originally designed to do, by the way, but it was putting the cart before the horse—you need to be able to do simple searches before you start looking for patterns). But what is the best way to rank real-time search results—by number of followers, retweets, some other variable? It is not exactly clear. But if Twitter doesn’t solve this problem, someone else will and they will make a lot of money if they do it right.
(Photo by Patrick Boury).