
Evri, a site that uses semantic searching to help users discover more Web content in the shortest amount of time, has added a number of new product features today to mark its open beta.
The site now features a content recommendation engine that publishers can add to their sites to let visitors browse Evri’s listings and profile pages where Evri will collect all the related content on a particular topic. In addition to videos, Evri also added an image carousel to its results pages, which it collects from across the Web.

The idea sounds fine — Evri wants to collect some of the best news, videos, photos, and important information from news sources, Wikipedia, and Google (to name a few) to create a more informative experience — but it falls flat on its face on too many levels.
Sure, it’s nice to have videos at my disposal on Evri’s page instead of searching for them on YouTube and it collects basic content from Wikipedia so I don’t have to surf my way around the Web, but most of the general information and news can be found on Wikipedia anyway. And while the images and videos are a plus, they are not enough to make me want to use Evri.
Not only that. The site is missing a slew of simple topics and on a major topic like Android, it only has seven “top” relevant news articles. If I did a simple search on Google News, I’d be able to find thousands.
I took Evri for a spin to make sure my initial distaste for the service wasn’t made in haste. Unfortunately, it wasn’t.
I first started out with something simple by searching for “Android.” The site returned an informative page on Google’s software and included information it collected from Wikipedia, YouTube, and elsewhere. I was surprised that the site’s image results displayed just two screenshots of Android’s interface. The rest were images having nothing to do with the software—some stills from a 1960s movie, a man rock climbing, a random drawing, and some shots of the iPhone and Blackberry. I then surfed over to Wikipedia and searched for Android and gleaned much more information about it. And considering the videos and images were a bit off, I didn’t miss much at all.
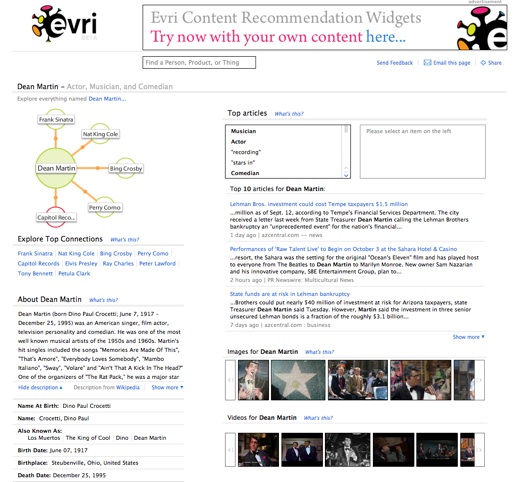
What about a person search? Many of the same problems persisted. I tried something a bit more obscure than “Bill Gates” and searched for “Dean Martin.” Finally, the site returned relevant images and a bunch of videos that proved extremely relevant. Only this time, the news results were crazy: the top result mentioned Lehman Brothers and its financial woes.
What amazed me most about Evri was the sheer number of sites, people, and companies that it doesn’t support. Granted, it’s still in beta and its public launch was just today, but it’s missing startups like Yammer and FriendFeed and relatively well-known dog breeds like golden retriever or airedale terrier.
Finally, Evri’s “Top Connections” functionality is a bit suspect. Once you find the result you’re looking for, you can click on the connections it formulates for the term. In other words, if you’re searching for Microsoft, the site will show a diagram with Microsoft in the middle and a series of circles with company names in them connected to it. If you click on one of those circles (Yahoo, for one), it’ll display news articles pertaining to both Microsoft and Yahoo. Amazingly, those two companies only returned 10 top results — a ridiculously low number given their history.
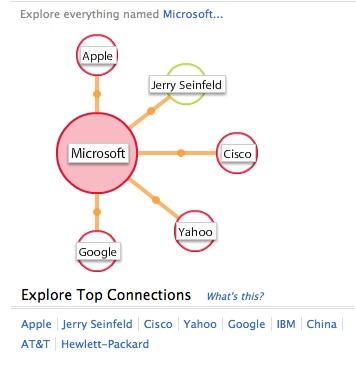
Here’s what that looks like for “TechCrunch”:
Evri is trying to make the Web simpler for its users, which is probably why it doesn’t list so many news results and keeps the descriptions it collects from Wikipedia to a minimum. But because it chooses to do that, Evri quickly becomes a source for those who want quick access to videos and not much more. If you’re looking for in-depth knowledge about a given subject, Evri simply falls short of its aspirations.
And perhaps that’s why it was lost on me. I can get all that information elsewhere and chances are, I’ll be able to find better information much faster. If this is the best the Semantic Web has to offer, it still has along way to go.