Update: Overview videos of the new service and a white paper are here.
Digg has been talking up a new Recommendation Engine that intelligently suggests new stories to users for almost a year. Well, a source says that the company will launch it soon, probably this week. We have some details and a couple of leaked screen shots, which may or may not be real (I’m betting on real).
An average of 16,000 stories a day are submitted to Digg. Most users don’t venture past the handful of popular stories that make the home page. A few brave souls, though, venture into the Upcoming sections, where all the rest of the stories sit until they expire (most of them) or get promoted to the Popular section.
The Upcoming section allows users to sort by category, freshness, number of diggs and number of comments, but the sheer volume of stories means it’s nearly impossible to find interesting news. The new Recommendation Engine section will be replacing Upcoming entirely from what we hear.
Recommendations will be made based on diggs from users who tend to vote in a similar way as you do: “The Recommendation Engine suggests upcoming stories by matching you with Diggers like you.” this is very similar to the way Netflix handles movie recommendations, although since every story on Digg has a shelf life of just 24 hours, it has to work in real time.
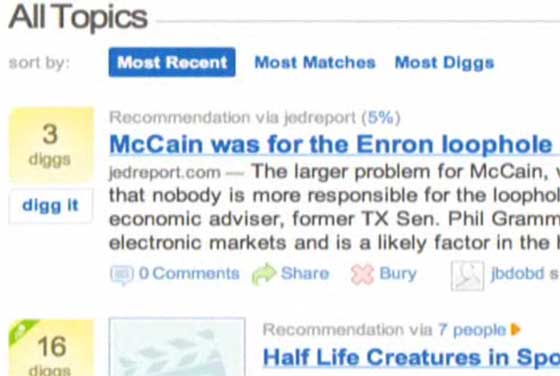
Based on the screen shots, users can see like-minded users in the right sidebar along with a compatibility percentage. If you click on one of the users you’ll see the overlap between your and his/her digg voting over the past 30 days (in this case, six stories), and see recommended stories from that user. Users will be able to sort recommended stories via most diggs, most matches, and most recent.
Presumably the users you are similar to will change over time, and there is a button at the top of the screen to remove any particular user if you don’t want to see their recommendations in the future.
My thoughts: it actually looks like a winner. If the algorithm works to properly match me to other users with similar interests, Digg can become the first place I check every day for interesting breaking news in a variety of categories, rather than the place I go when I have a few minutes to see just the massively popular stuff. It will be interesting to see if they get a pop in unique visitors and page views.
We also believe that the Recommendation Engine will be the official introduction of Lead Scientist Anton Kast, who joined the company in 2007 but has been very much behind the scenes until now. Kast reportedly led the project internally.
More screen shots below: