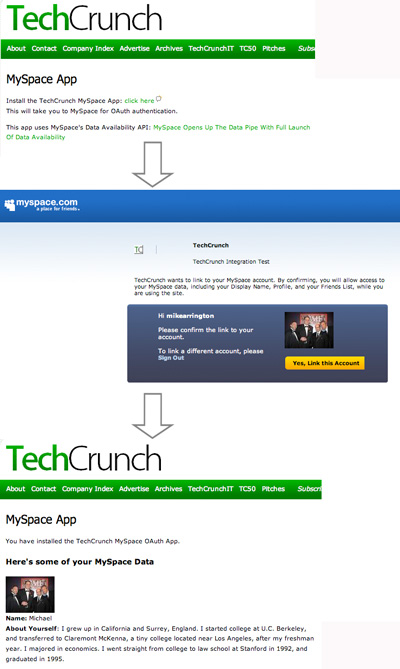
The CrunchBase guys (thanks Henry and Mark) have been hacking away at the newly launched MySpace Data Availability APIs to create a test application that is now working, at beta.techcrunch.com/myspace/app.php. You can sign into the account using your MySpace credentials and see a results page here on TechCrunch that contains your core profile information – your name, picture, bio, and list of top friends (we could grab more, but limited it to this).
MySpace doesn’t allow caching of information, so we dump it immediately after creating the results page. Also, MySpace is still finalizing some of the APIs, and their developer servers are also getting hit pretty hard right now. As a result, we’re seeing result errors approximately 50% of the time on our test app. This should clear up soon.
This is just a sample data dump, but it shows the potential of the service, which we called a real step forward in terms of user data rights and data portability. I am sure we will shortly be seeing some very creative uses of the product (including by Twitter, Ebay and Yahoo, who are all announced partners of Data Availability).
Update (Henry Work): The source code for the app is now freely available on GitHub: github.com/techcrunch/myspace_oauth/.