MySpace was the first of the Big Three to announce tools for third party sites to integrate MySpace user data into their services (called, collectively, Data Availability). A day later Facebook announced Facebook Connect, then came Google Friend Connect three days after that.
Today MySpace is fully launching Data Availability (look for it this afternoon at developer.myspace.com), and any third party developer can now build applications using their APIs. Google’s product remains in a test phase with a handful of sites (example), and we won’t likely hear more from Facebook until their F8 conference in late July.
MySpace is taking a much more interesting approach than Google, which controls data sent to third party sites via an iframe. MySpace is actually streaming data to these sites, which allows for true integration between the services, not just a bolted-on social tool.
Developers can access any publicly available profile data from a MySpace user and integrate it into their site. This includes a user’s name, picture, bio, social graph (list of friends), and other information. Users authorize the data transfer via a one-time secure OAuth login to MySpace from the third party service. The service is then allowed to access the data.
Since actual data is being streamed out of MySpace, they have a strict terms of use policy that forbids third party sites from storing or caching the data, other than the unique MySpace user id of the user. Each time a page is rendered the third party must re-request the data from MySpace via a set of APIs. That means any changes by the user to their MySpace profile data or friends list will be instantly applied across third parties who access the data.
Like Google and Facebook, users will be able to revoke access by any third party via a privacy control panel on their MySpace account:
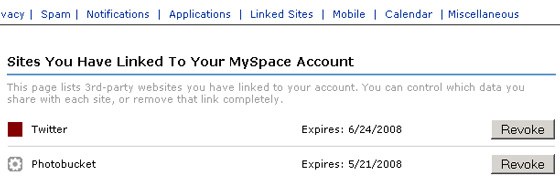
Actual Data Portability, But No Syncing
This is a real move towards data portability, since MySpace is actually allowing data out of its server vault. The fact that third parties can’t store that data isn’t a perfect solution, since MySpace retains ultimate control of it (I discuss this problem in my Centralized Me post). True data portability requires constant syncing of data so that the users remain in control. But until real standards emerge on just how to do that (and there are some big hurdles), MySpace’s approach seems more than reasonable. This is a real step forward in terms of user data rights, and I expect we’ll see a ton of very creative implementations of Data Availability.
We are building a test application now and should have it live within a few hours. Look for lots of implementations over the next few days.