How much are your friends worth? That is the question behind the big debate going on around social networks and data portability. In the last ten days, Facebook, Google, and MySpace have all announced ways to let people access their data (including friends lists) from other sites, except that what they are really trying to do is erect new walled gardens by positioning themselves as the primary repository of that personal and social data. This is valuable data and none of the big players want to cede any more of it than is necessary, which is why Facebook banned Google from tapping into its members’ social data.
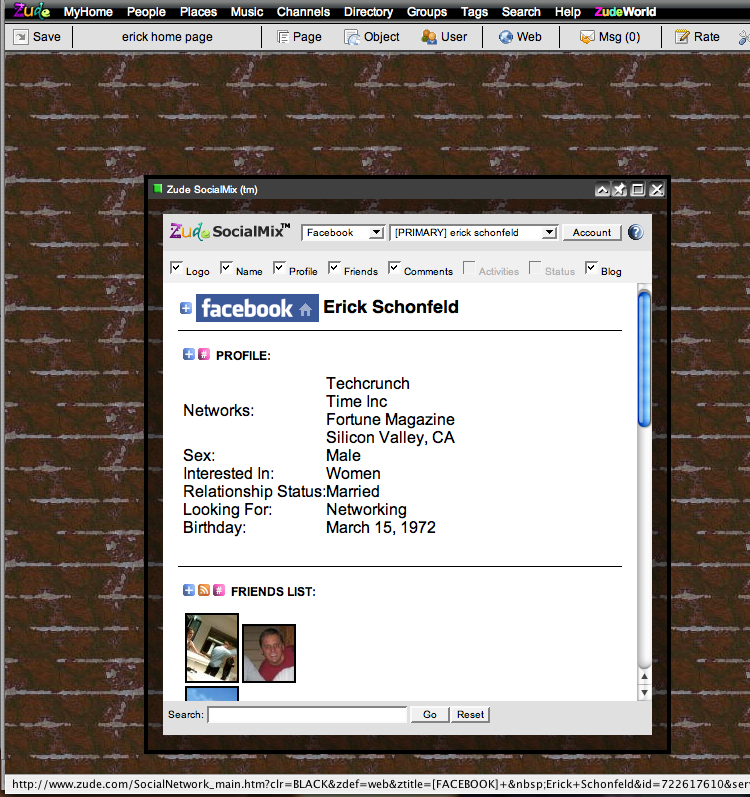
But here’s a little secret. All of this data is already leaking out in ways that Facebook and other social networks can hardly control. Startups are finding ways around their official APIs to get the data consumers want into their own systems. For instance, Zude, a personalized Webpage service, recently launched a feature called SocialMix that lets people import friends lists, photos, profile information, status updates, comments, and other data from Facebook, MySpace, Bebo, Orkut, and hi5. (See the screen shot below, which shows my Facebook friends on Zude). “What we are doing is taking the information and normalizing it and making it available in any manner you want,” claims Zude CTO Steve Repetti. He was tired of waiting around for true data portability to arrive, so he figured out a hack to offer it on his own (and it doesn’t involve screen scraping).
Taking a different approach, Minggl has found a way to access your social data through a browser plug-in. And Media6° is placing cookies through the ads themselves on Facebook to collect social data for advertisers. If you click on an ad with one of its cookies, then the same ad will be shown to all of your friends, who supposedly are two to ten times more likely to click on the ad than other people. Media6° also should be able to target Facebook members as they wander across the Web (as long as a cookie has been placed in their browsers and they come across an ad with the Media6° Javascript code embedded in it).
I’ve come across other startups who claim to be able to pull profile and friend data from Facebook. Facebook can go after them and shut them down, but it is rightly more concerned about Google gaining free and unfettered access to that data. Google is the bigger competitor and the bigger threat. But in the meantime, all of these little startups are finding ways to get at the same social data being so ferociously guarded by Facebook. In fact, they already have it, and Facebook is going to have a hell of a time trying to put it back in the barn.
(Photo by Larry Wilder).