![]() Yahoo is following in Google’s footsteps again in search. Today, it is shifting a crucial part of its search engine to Hadoop, software that handles large-scale distributed computing tasks particularly well. Hadoop is an open-source implementation of Google’s MapReduce software and file system. It takes all the links on the Web found by a search engine’s crawlers and “reduces” them to a map of the Web so that ranking algorithms can be run against them. (Update: A second try at explaining this. What MapReduce and Hadoop do is break up a computation problem into mangeable chunks and distribute them to different processors—that is the “map” part, it is mapping the data. Once all of the individual results are in, they are combined into one big result—that is the reduce part. Search engines, in turn, use this technique to literally map the Web. Sorry for any confusion my paraphrasing might have caused.)
Yahoo is following in Google’s footsteps again in search. Today, it is shifting a crucial part of its search engine to Hadoop, software that handles large-scale distributed computing tasks particularly well. Hadoop is an open-source implementation of Google’s MapReduce software and file system. It takes all the links on the Web found by a search engine’s crawlers and “reduces” them to a map of the Web so that ranking algorithms can be run against them. (Update: A second try at explaining this. What MapReduce and Hadoop do is break up a computation problem into mangeable chunks and distribute them to different processors—that is the “map” part, it is mapping the data. Once all of the individual results are in, they are combined into one big result—that is the reduce part. Search engines, in turn, use this technique to literally map the Web. Sorry for any confusion my paraphrasing might have caused.)
Yahoo is replacing its own software with Hadoop and running it on a Linux server cluster with 10,000 core processors. The Hadoop software does the same job 34 percent faster than the old software. Yahoo is also providing some other interesting stats that gives us a view into the computing infrastructure behind its search engine:
Some Webmap size data:
* Number of links between pages in the index: roughly 1 trillion links
* Size of output: over 300 TB, compressed!
* Number of cores used to run a single Map-Reduce job: over 10,000
* Raw disk used in the production cluster: over 5 Petabytes
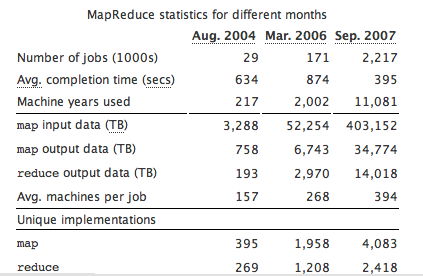
Compare this to some data from Google on its MapReduce computing infrastructure (it is not quite apples to apples, but Google was processing 20 petabytes a day back in September, 2007 and outputting 14,000 terabytes in compressed data per month):
Hadoop is a project of the Apache Software Foundation. It also works for large-scale computing problems beyond search. For instance, IBM is using Hadoop as a foundation for its cloud computing initiative. Competing with Google using open-source software where it can is a smart move on Yahoo’s part, especially when that software outperforms its own.