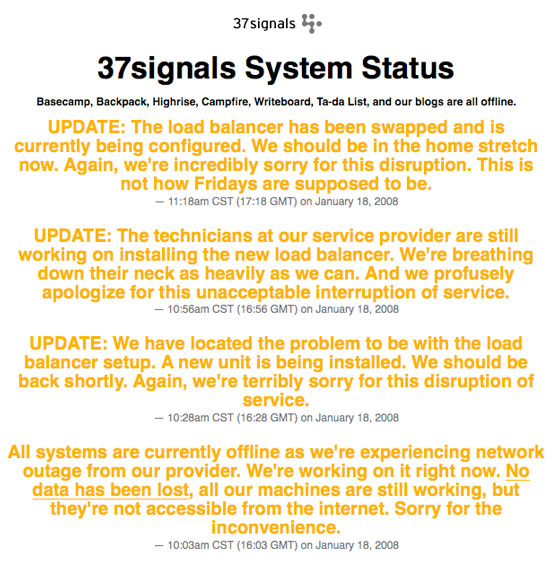
37Signals is having a bad morning, according to their current home page image above. They’re pointing fingers at their service provider, which was (and we believe still is) Rackspace. Last November they suffered a three hour outage along with other Rackspace customers.
Update: It’s back up, total outage was about 2 hours. Per the comments, 37Signals doesn’t seem super duper happy with Rackspace these days.