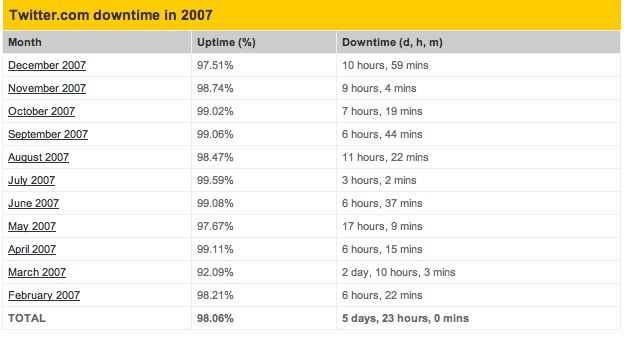
Even after moving to a new data center, Twitter has been undergoing some growing pains. Royal Pingdom reports that the service has been down almost a total of six days since it began monitoring the service last February. Downtime so far in December has exceeded almost any preceding month, with nearly 11 hours of downtime, compared to 9 hours in November.
I guess everyone is trying to get onto that Tweeterboard.