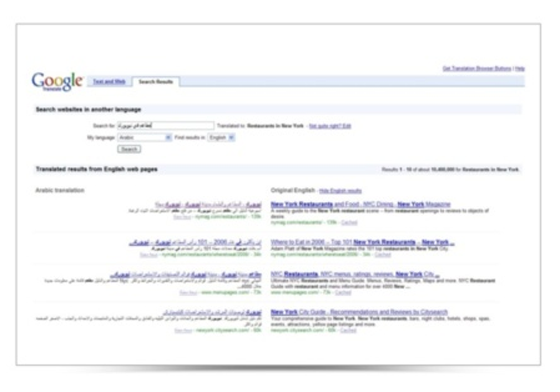
Udi Manber, VP Engineering at Google (and former CEO of Amazon’s A9) just announced at the Searchology event that Google will “soon” announce a cross-language search engine. Screen shot of the user interface is above.
To return more results, queries will be auto translated into other languages to retrieve more results, and all results will then be translated back into the original query language. The goal is to return many more results for queries, particularly queries done in less popular languages.
The screen shot is extremely poor quality (I apologize), but it shows arabic results on the left, translated from English results on the right.