Update 12/25/06: Jimmy Wales says this isn’t a Wikiasari screen shot. So what is it?
The Times reported earlier today that Wikipedia founder Jimmy Wales is planning to launch a new search engine next year, to be called Wikiasari.
He’s clearly aiming for Google. He says:
“Google is very good at many types of search, but in many instances it produces nothing but spam and useless crap. Try searching for the term ‘Tampa hotels’, for example, and you will not get any useful results…Essentially, if you consider one of the basic tasks of a search engine, it is to make a decision: ‘this page is good, this page sucks.’ Computers are notoriously bad at making such judgments, so algorithmic search has to go about it in a roundabout way…But we have a really great method for doing that ourselves. We just look at the page. It usually only takes a second to figure out if the page is good, so the key here is building a community of trust that can do that.”
The new company will be the third business division of Wikia, the for profit company that Wales founded in 2005 and is now led by CEO Gil Penchina. The other two business units are the main Wikia wiki site itself, and the recently launched OpenServing product.
Wikia has raised over $4 million in capital, including a recent round by Amazon.
Despite the fact that the original article reported that Amazon is involved in the project, Wikia is making it clear on the site that they are not invovled in any way (other than as a shareholder of Wikia).
Wikiasari
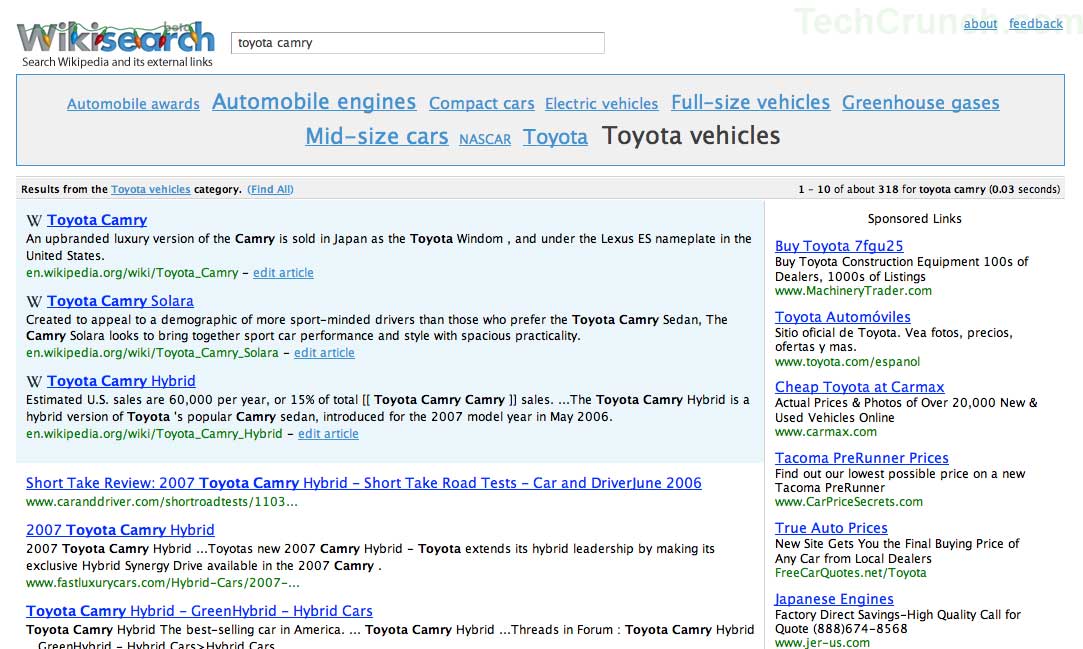
A source tells us that the working name for the project was “WikiSearch” until recently. It’s clear that Wikiasari will be focused on quality first, depth second. Search results will include tag based navigation, the top three results will be wikipedia content, and the remaining results are determined by sites wikipedia considers to be “reputable” because they are external reference links from wikipedia pages.
Since all search results will be tied to wikipedia, either directly by linking to wikipedia content or because the sites are linked to from Wikipedia, real people will eventually be determining all search results and rankings within Wikiasari. The search engine will be opensource, and the index will be available under a GFDL. Wikia will operate the master version of the index, but others are free to take it under the terms of the GFDL.
The engine itself will be built on the Nutch and Lucene open source projects.
Wikiasari will be a for profit venture, although the “majority” of proceeds will be donated to Wikipedia.
We obtained the screenshot from a trusted source outside of Wikipedia – we can’t guarantee it’s not a fake but our belief is that this is a genuine working screenshot of the application. Click on it to see full size version.