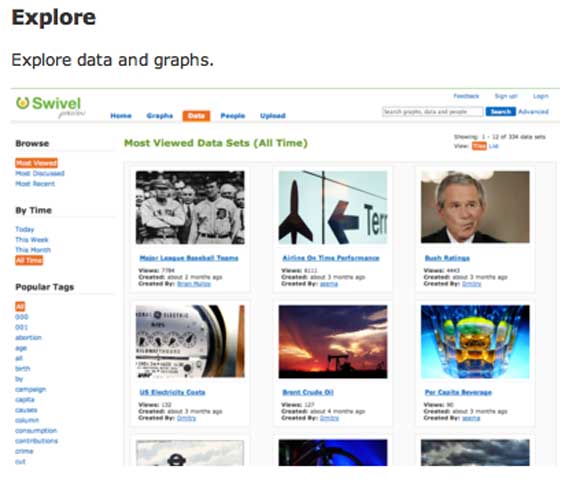
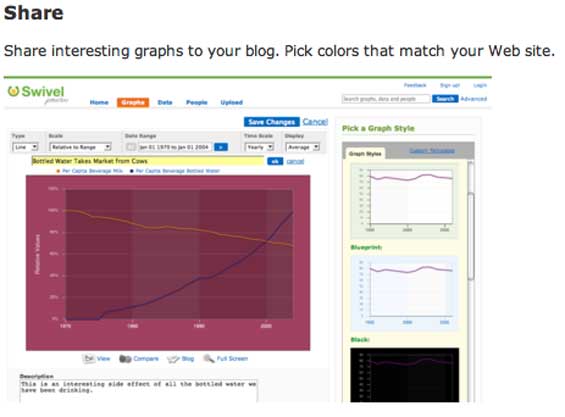
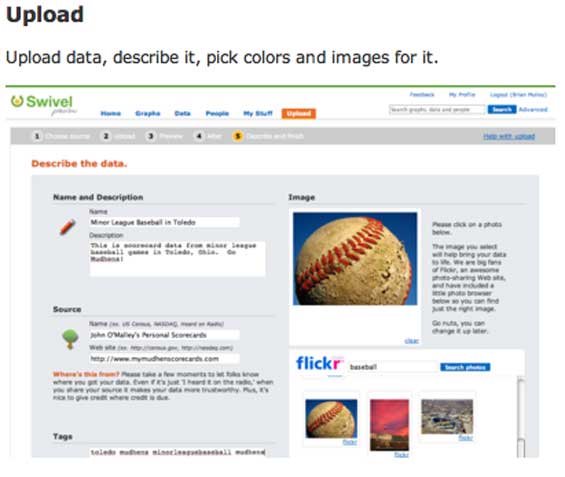
Swivel Co-founders Dmitry Dimov and Brian Mulloy start off by describing their company as “YouTube for Data.” That’s a good start for someone trying to understand it, because the site allows users to upload data – any data – and display it to other users visually. The number of page views your website generates. Or a stock price over time. Weather data. Commodity prices. The number of Bald Eagles in Washington state. Whatever. Uploaded data can be rated, commented and bookmared by other users, helping to sort the interesting (and accurate) wheat from the chaff. And graphs of data can be embedded into websites. So it is in fact a bit like a YouTube for Data.
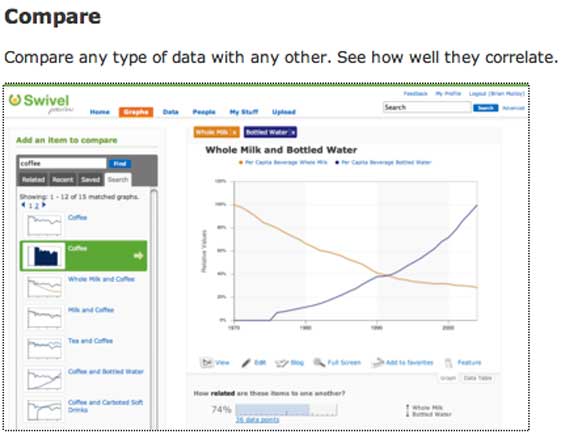
But then the real fun begins. You and other users can then compare that data to other data sets to find possible correlation (or lack thereof). Compare gas prices to presidential approval ratings or UFO sightings to iPod sales. Track your page views against weather reports in Silicon Valley. See if something interesting occurs.
And better yet, Swivel will be automatically comparing your data to other data sets in the background, suggesting possible correlations to you that you may never have noticed.
Academic types are going to go nuts over this. I spent a summer in college running regression analysis models on economic data. Being able to simply upload data to Swivel and then begin to slice and dice the data would have saved a lot of time. And being able to compare our data to what others were doing in related fields could have yielded results that we would never have aimed for. Big companies, small companies, thinktanks and non-classified government organizations are going to be similarly dazzled.
Swivel is putting significant computing power behind the scenes to run the data analysis. “We use farms of powerful computers and algorithms at the Swivel data centers to transform a lonely grid of numbers and letters into hundreds – sometimes thousands – of graphs that can be explored and compared with any other public data in Swivel.”
Not all data will be public. The companies business model is to provide the service for free for public data, and charge a fee for data that is kept private. Private data can still be compared by the owner to public data sets.
Look for Swivel to launch later this week after a year of quiet development. The company is based in San Francisco and is part of Minor Ventures.
Exclusive screen shots below: