Portland, Oregon based AboutUs announced this week that it has closed a Series A round of funding and raised $1 million. The site is a wiki directory of web sites, mostly populated automatically but with a healthy amount of traffic and a growing number of edits being made daily. If you look up your website on AboutUs, you’ll probably find an entry there. I expect most people who aren’t wiki lovers to think this is a strange business and to some degree I think it is too. It’s also very interesting and has some good people behind it.
Sixteen investors total participated in the round, with Capybara Ventures and Northwest Technology Venture providing institutional backing. AboutUs founder Ray King was co-founder and CEO of SnapNames. The Board of Advisors for AboutUs includes wiki forefather Ward Cunningham, Stephen Babson of Endeavour Capital and Keith Teare of Edgeio. The AboutUs site went live in August and has seen healthy traffic growth. The site’s traffic after only a few months is one of its primary selling points.
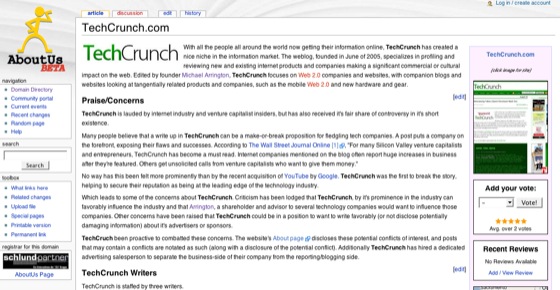
AboutUs is built on MediaWiki, the same platform that Wikipedia runs on. It’s not the prettiest thing in the world to look at, but it’s functional. There are entries for about 3 million websites in the wiki. The vast majority are populated from Whois records, with related links and a Google Map added for each page. The 5 person company personally checks all edits each night, now between one and two thousand on average. (Founder Ray King says that adding the words “can I really change this?” is the most common edit people make to the site.) There isn’t a neutral point of view requirement, but review type text is encouraged to be placed in a special section for reviews.
There is something that bothers me about having 3 million pages about websites, populated automatically and by any random editor who stops by, titled “AboutUs.” The phrase implies an autobiographical text. (It’s also probably very good for SEO.) The AboutUs page on TechCrunch wasn’t written by anyone associated with TechCrunch and there’s something about the name AboutUs that makes me uncomfortable about that. I could certainly go in and change the entry, but it feels more like something I’m obligated to do unless I ignore it.
The company has partnerships with a number of domain registrars in the works to put links to each site’s AboutUs page at the top of WhoIs info, in exchange for a badge linked back to that registrar. King hopes that a growing number of websites will put links to their AboutUs.org pages on their sites, as he intends to add wiki functionality and a community edited About page to every site on the web that he can.
The site hasn’t been monetized yet; Ray King says they will explore premium features like paid job listings on company pages. I probed ruthlessly for some indication of an antisocial profit drive in King, as it took me a while to believe that a business based on content scraped from the WhoIs records of other sites could be legitimate. In the end, though, I was convinced that King really is a true believer in “the wiki way,” as he calls it, a collaborative culture based on presumptions of good faith.
Presumptions of good faith aside, I’d like at the very least an RSS feed to subscribe to changes being made to sites I’m connected to. King says that’s a high priority and will soon be one of a number of extensions he’s made to his MediaWiki implementation.
Can AboutUs succeed? If it does, it will be part of a general transition of the culture of the web. I like the idea of having wiki guides to websites, though calling it AboutUs makes me uncomfortable and I hope a wave of nasty edits doesn’t make me regret pointing to it. If a happy medium of wiki purity and some control over edits can be maintained, AboutUs could be well positioned in a world still deciding how it feels about “the wiki way.”